本文共 1769 字,大约阅读时间需要 5 分钟。
作者
日期
2018-05-02
标签
文件恢复, Hbase, Ext4, ext4magic, extundelete , 删库
前言
误删库(删文件) 是生产运维中最严重的故障。Hadoop大数据环境下,数据的备份与恢复都面临比传统数据库更加严峻的挑战。
作者参加的一次Hbase删库故障恢复中,由于所用Hbase版本旧,未支持snapshot的备份机制,未做任何备份。在删库误操作发出5分钟后,操作人员取消了命令,并停止了外部业务对Hbase的访问。根据日志,删除命令已发送到datanode节点,hadoop文件目录下,只有一个数据文件(128M),故障前有效数据在几个T。由于发生故障后,很快停止了对故障机器的访问,操作系统应该只是标记了文件的删除,实际数据应该在操作系统内核层面可见。
由于删除操作涉及了大量的文件,导致Ext4中的Journal日志被覆盖,无法恢复出所有的文件元信息。因此恢复的技术路线是直接在ext4层面读取数据块,根据hbase格式直接解析内容(特征码扫描方式)。下面梳理与描述了Ext4 文件恢复的大致原理,供各位同学参考。debugfs与ext4magic具体的操作流程,等有空再整理。
Ext4中目录与文件的存储结构
在分区根目录下创建文本文件1.txt,写入文件内容abc。

简单说,ext4中文件和目录包含元数据和实际数据两个部分,实际数据存储了文件的实际内容,元数据存储了文件的创建修改删除时间以及实际数据的地址。文件和目录的元数据由一个inode结构表示。所有的inode存储在inode数组中,根据序号访问。
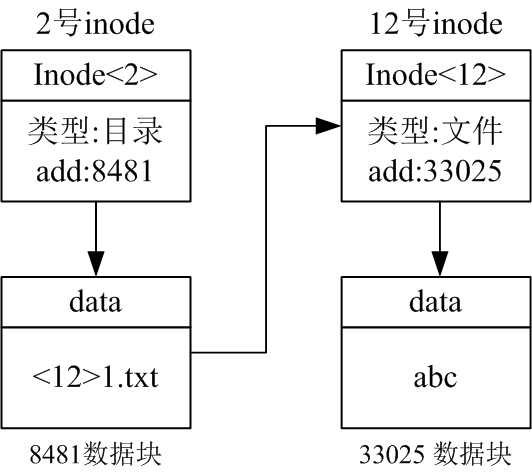
下图描述了目录与文件的逻辑关系图。分区根目录inode序号默认为2,2号inode中记录了目录数据块的位置8481。8481数据块中存储了该目录下文件的inode序号和文件名,1.txt的inode序号为12。12号inode指向的数据块为33025,33025中存储了2.txt实际内容abc。(add表示地址,块号)
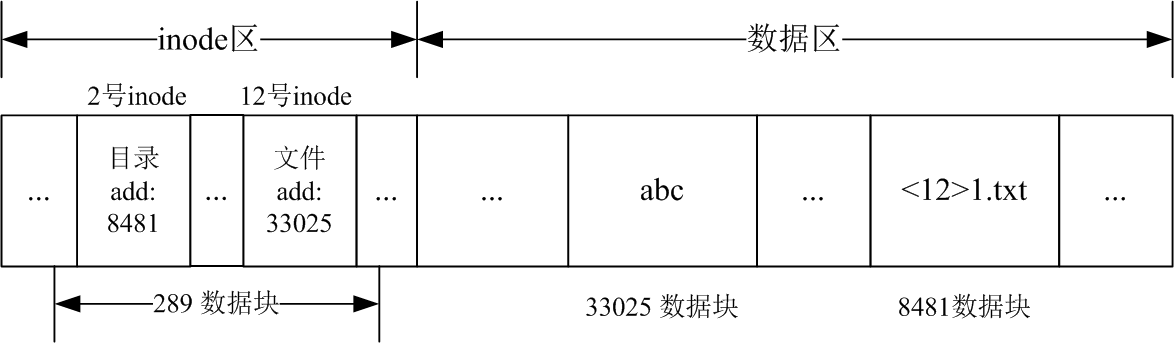
下图描述了目录和文件存储的物理结构图。
删除文件后的目录与文件结构
执行 rm -f 1.txt
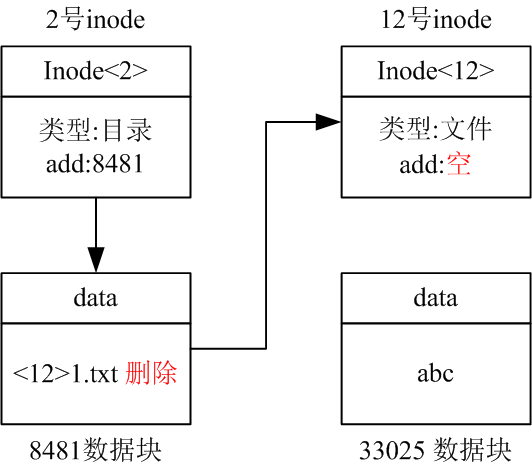
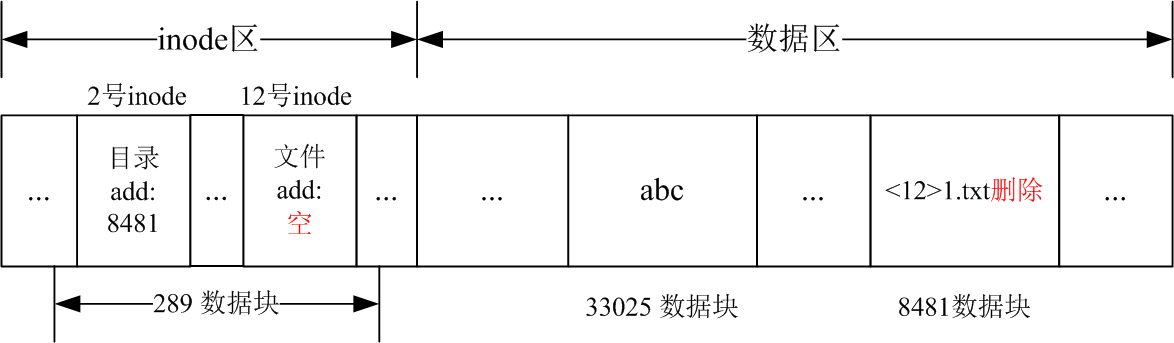
下图为删除1.txt后,目录与文件的逻辑和物理结构。/目录的内容中标记了1.txt已经删除,ls操作不会显示已经被标记为删除的文件。12号innode中的地址信息被清除。因此文件删除后,虽然可以找到删除文件的名字,但是无法确定其数据块位置,从而无法恢复数据。
journal日志
ext3和ext4文件系统,使用日志机制实现了写文件的原子性和故障恢复。
在根目录中创建文件1.txt,写入内容,删除该文件,三个操作分别对应三个事务。每个事务中会记录操作涉及的元数据所在的数据块(数据块为操作后的新值,而不是操作前的值,为REDO日志而不是UNDO日志)。
下图为三个操作的事务日志简化描述(实际情况下删除一个文件占用6个左右的数据块),与之前的数据块描述对应。每个框均表示为一个单独的4K Block。除事务的开始和结束块,其他均为操作修改的数据块的REDO值。
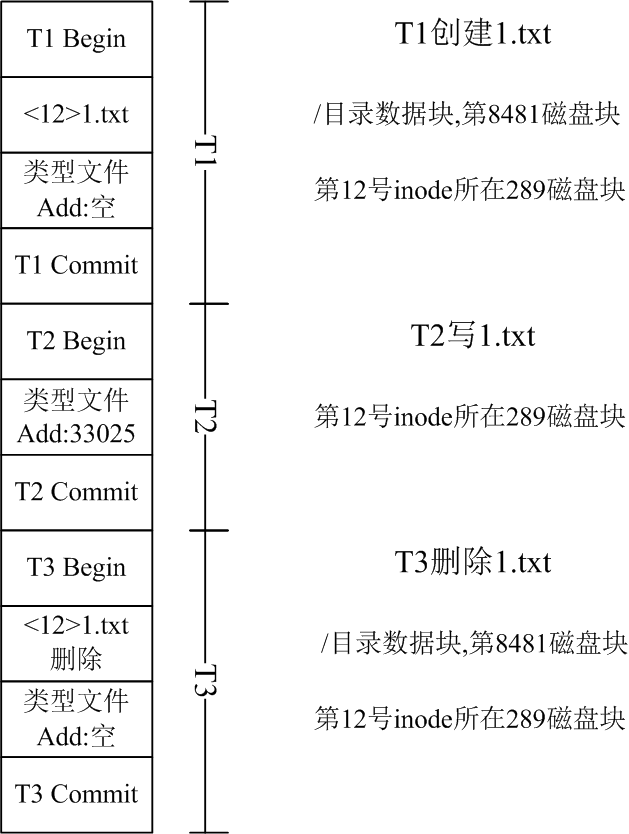
根据journal恢复
文件1.txt删除后,其数据所在8481磁盘块的内容还在,但是inode表到该磁盘块的链接被清除,无法用于恢复操作。
journal日志文件中,有T1,T2,T3三个事务日志,T3和T1日志中的第12号inode不包含add信息,T2事务中的第12号inode包含add信息,可用于恢复数据。
因此删除操作本身的journal日志不能用于恢复,journal中必须有删除操作之前的inode信息才能进行恢复。
journal日志文件大小固定,在128M大小情况下,有32768个文件块,在日志写满后,会重复循环使用文件。如果在journal日志中,无法找到有效的文件inode信息,则该文件无法恢复。
ext4magic恢复机制
ext4magic恢复包括4个步骤,其中前3步根据journal文件日志中的有效inode信息进行数据恢复,当不能完成恢复时,第4步进行全盘扫描,根据文件的具体格式(特征码)进行恢复,支持包括以下类型文件。不能支持记录跨块的情况。

该方式,与直接扫描磁盘进行hbase记录解析原理相同。
参考
版权声明:自由转载-非商用-非衍生-保持署名